Appearance
链表
单向链表
单向不循环链表是一种单向的链式结构,节点之间通过指针域互相关联,最后一个节点的指针域为空(NULL)。
单向链表采用了链式存储的方式来实现,链表中的各个结点的内存地址是不连续的,我们可以通过当前结点找到下一个结点。结合线性结构和链式存储的特性,我们来设计单向链表。
链表中最简单的一种是单向链表,它包含两个域,一个信息域和一个指针域。这个链接指向列表中的下一个节点,而最后一个节点则指向一个空值。
一个单向链表包含两个值: 当前节点的值和一个指向下一个节点的链接 一个单向链表的节点被分成两个部分。第一个部分保存或者显示关于节点的信息,第二个部分存储下一个节点的地址。单向链表只可向一个方向遍历。
链表最基本的结构是在每个节点保存数据和到下一个节点的地址,在最后一个节点保存一个特殊的结束标记,另外在一个固定的位置保存指向第一个节点的指针,有的时候也会同时储存指向最后一个节点的指针。一般查找一个节点的时候需要从第一个节点开始每次访问下一个节点,一直访问到需要的位置。但是也可以提前把一个节点的位置另外保存起来,然后直接访问。当然如果只是访问数据就没必要了,不如在链表上储存指向实际数据的指针。这样一般是为了访问链表中的下一个或者前一个(需要储存反向的指针,见下面的双向链表)节点。
相对于下面的双向链表,这种普通的,每个节点只有一个指针的链表也叫单向链表,或者单链表,通常用在每次都只会按顺序遍历这个链表的时候(例如图的邻接表,通常都是按固定顺序访问的)。
创建
查看
插入
删除
更新
双向链表
一种更复杂的链表是“双向链表”或“双面链表”。每个节点有两个连接:一个指向前一个节点,(当此“连接”为第一个“连接”时,指向空值或者空列表);而另一个指向下一个节点,(当此“连接”为最后一个“连接”时,指向空值或者空列表)
一个双向链表有三个整数值: 数值, 向后的节点链接, 向前的节点链接 在一些低级语言中, XOR-linking 提供一种在双向链表中通过用一个词来表示两个链接(前后),我们通常不提倡这种做法。
双向链表也叫双链表。双向链表中不仅有指向后一个节点的指针,还有指向前一个节点的指针。这样可以从任何一个节点访问前一个节点,当然也可以访问后一个节点,以至整个链表。一般是在需要大批量的另外储存数据在链表中的位置的时候用。双向链表也可以配合下面的其他链表的扩展使用。
由于另外储存了指向链表内容的指针,并且可能会修改相邻的节点,有的时候第一个节点可能会被删除或者在之前添加一个新的节点。这时候就要修改指向首个节点的指针。有一种方便的可以消除这种特殊情况的方法是在最后一个节点之后、第一个节点之前储存一个永远不会被删除或者移动的虚拟节点,形成一个下面说的循环链表。这个虚拟节点之后的节点就是真正的第一个节点。这种情况通常可以用这个虚拟节点直接表示这个链表,对于把链表单独的存在数组里的情况,也可以直接用这个数组表示链表并用第0个或者第-1个(如果编译器支持)节点固定的表示这个虚拟节点。
创建
查看
插入
删除
更新
实现学生管理系统
对学生的信息进行增删改查相关的操作, 并用链表来实现.
思考题
- 将学生的信息数据存储到文件中.(系统编程中, 将学习对文件的操作)
- 可以使用地本提供的数据库. sqlite (这是用C++写的数据库)
算法
跳表算法
跳跃表(skiplist)是一种随机化的数据, 由 William Pugh 在论文《Skip lists: a probabilistic alternative to balanced trees》中提出, 跳跃表以有序的方式在层次化的链表中保存元素, 效率和平衡树媲美 —— 查找、删除、添加等操作都可以在对数期望时间下完成, 并且比起平衡树来说, 跳跃表的实现要简单直观得多。
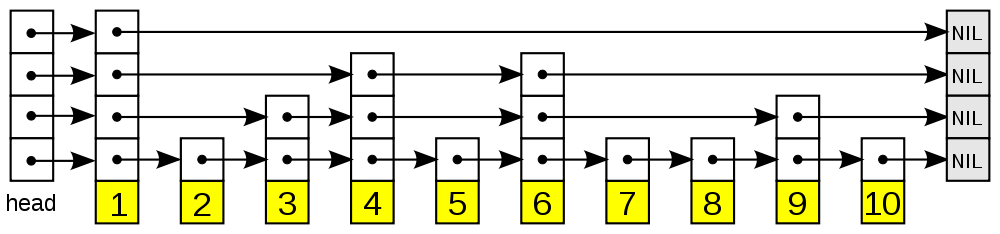
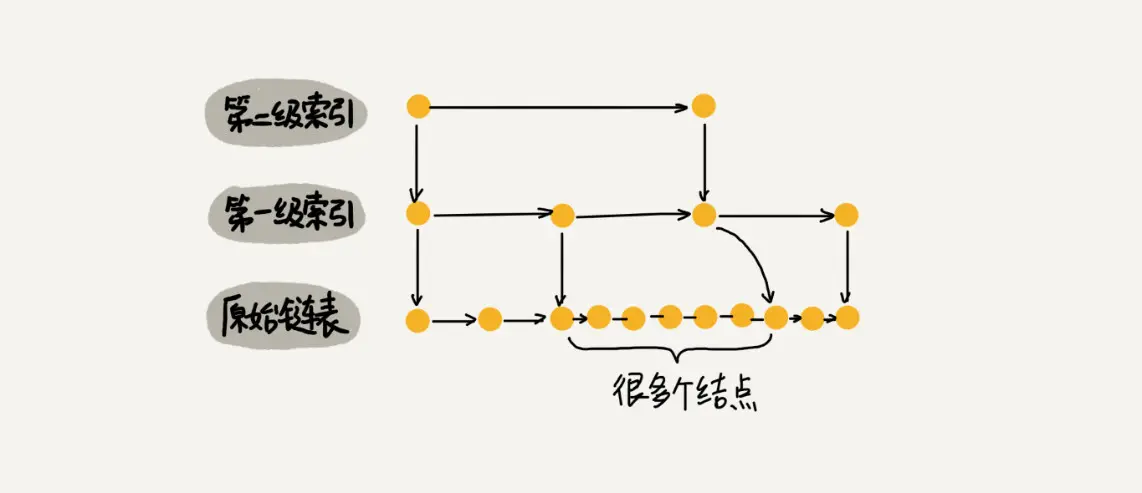
从图中可以看到, 跳跃表主要由以下部分构成:
- 表头(head):负责维护跳跃表的节点指针。
- 跳跃表节点:保存着元素值,以及多个层。
- 层:保存着指向其他元素的指针。高层的指针越过的元素数量大于等于低层的指针,为了提高查找的效率,程序总是从高层先开始访问,然后随4着元素值范围的缩小,慢慢降低层次。
- 表尾:全部由 NULL 组成,表示跳跃表的末尾。
实现链表的二分查找. 时间复杂度为
跳表创建
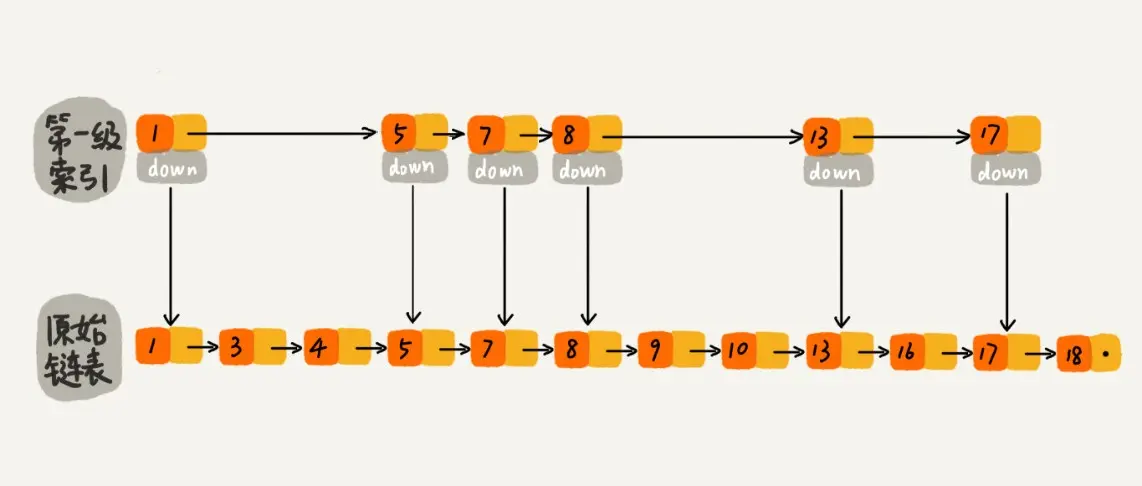
下图是一个简单的有序单链表,单链表的特性就是每个元素存放下一个元素的引用。即:通过第一个元素可以找到第二个元素,通过第二个元素可以找到第三个元素,依次类推,直到找到最后一个元素。
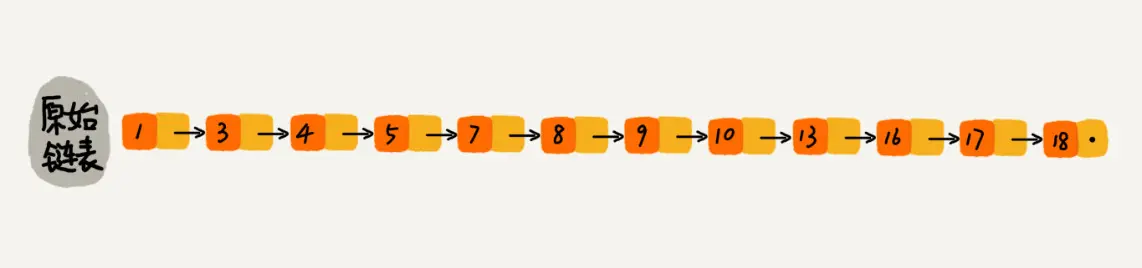
现在我们有个场景,想快速找到上图链表中的 10 这个元素,只能从头开始遍历链表,直到找到我们需要找的元素。查找路径:1、3、4、5、7、8、9、10。这样的查找效率很低,平均时间复杂度很高O(n)。那有没有办法提高链表的查找速度呢?如下图所示,我们从链表中每两个元素抽出来,加一级索引,一级索引指向了原始链表,即:通过一级索引 7 的down指针可以找到原始链表的 7 。那现在怎么查找 10 这个元素呢?
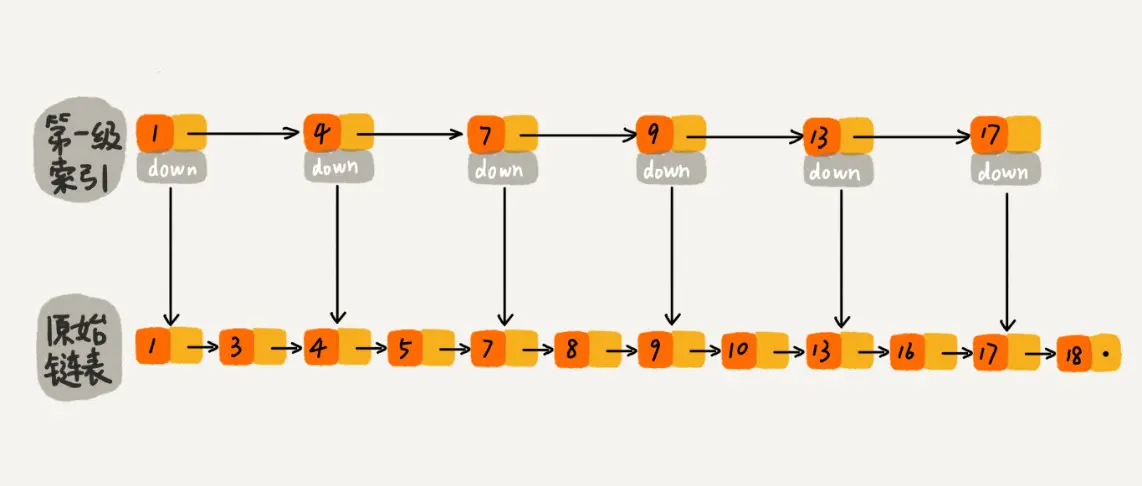
先在索引找 1、4、7、9,遍历到一级索引的 9 时,发现 9 的后继节点是 13,比 10 大,于是不往后找了,而是通过 9 找到原始链表的 9,然后再往后遍历找到了我们要找的 10,遍历结束。有没有发现,加了一级索引后,查找路径:1、4、7、9、10,查找节点需要遍历的元素相对少了,我们不需要对 10 之前的所有数据都遍历,查找的效率提升了。
那如果加二级索引呢?如下图所示,查找路径:1、7、9、10。是不是找 10 的效率更高了?这就是跳表的思想,用“空间换时间”,通过给链表建立索引,提高了查找的效率。
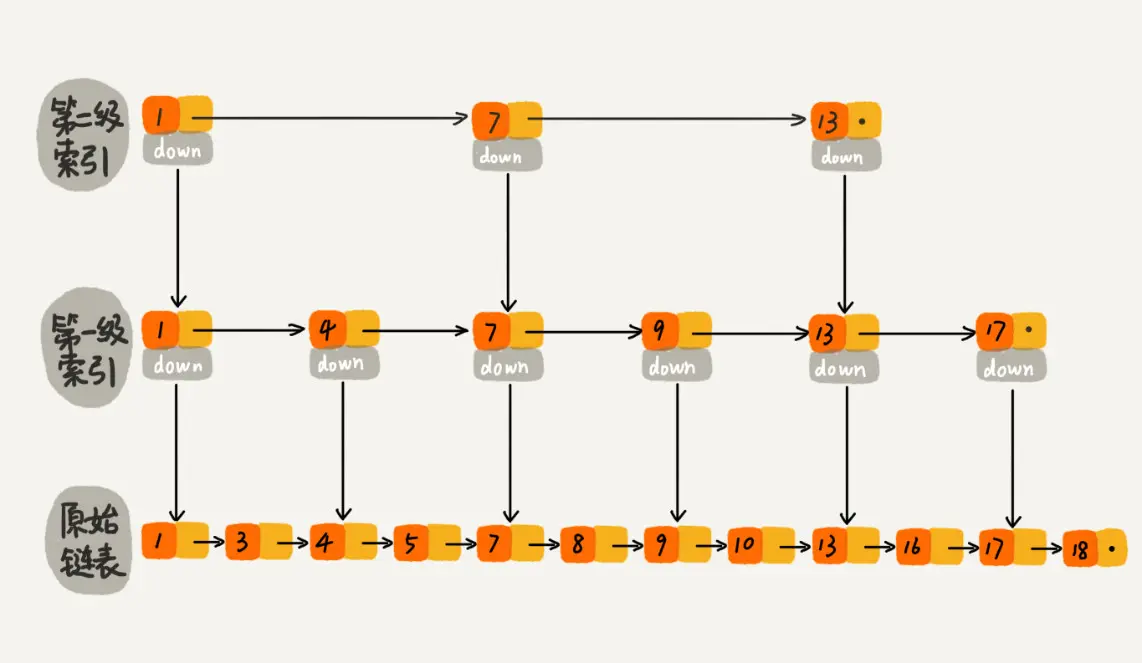
跳表的查找
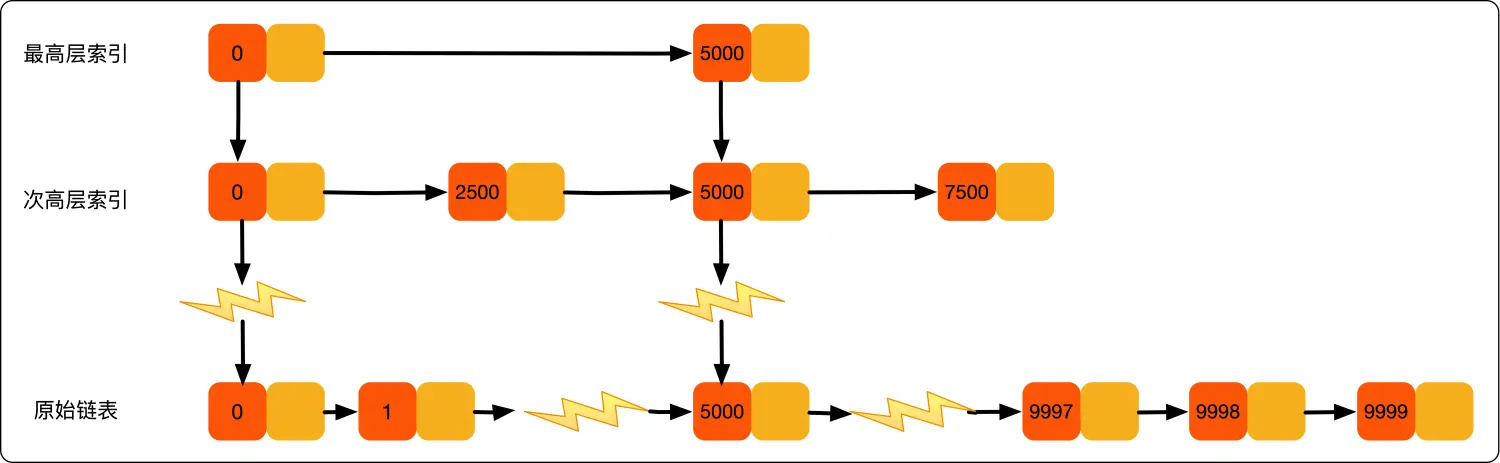
可能同学们会想,从上面案例来看,提升的效率并不明显,本来需要遍历8个元素,优化了半天,还需要遍历 4 个元素,其实是因为我们的数据量太少了,当数据量足够大时,效率提升会很大。如下图所示,假如有序单链表现在有1万个元素,分别是 0~9999。现在我们建了很多级索引,最高级的索引,就两个元素 0、5000,次高级索引四个元素 0、2500、5000、7500,依次类推,当我们查找 7890 这个元素时,查找路径为 0、5000、7500 ... 7890,通过最高级索引直接跳过了5000个元素,次高层索引直接跳过了2500个元素,从而使得链表能够实现二分查找。由此可以看出,当元素数量较多时,索引提高的效率比较大,近似于二分查找。
时间复杂度
既然跳表可以提升链表查找元素的效率,那查找一个元素的时间复杂度到底是多少呢?查找元素的过程是从最高级索引开始,一层一层遍历最后下沉到原始链表。所以,时间复杂度 = 索引的高度 * 每层索引遍历元素的个数。
先来求跳表的索引高度。如下图所示,假设每两个结点会抽出一个结点作为上一级索引的结点,原始的链表有n个元素,则一级索引有n/2 个元素、二级索引有 n/4 个元素、k级索引就有 n/2k个元素。最高级索引一般有2个元素,即:最高级索引 h 满足 2 = n/2h,即
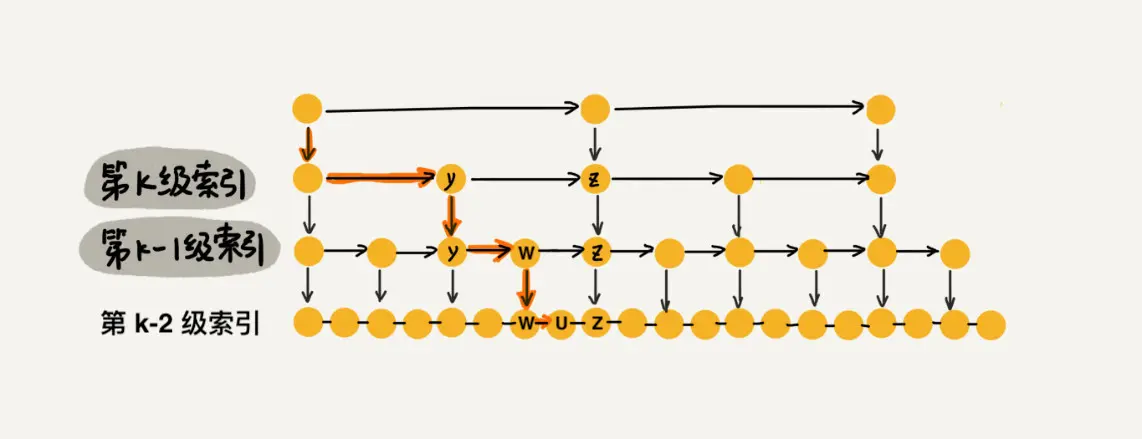
我们看上图中加粗的箭头,表示查找元素 x 的路径,那查找过程中每一层索引最多遍历几个元素呢?
图中所示,现在到达第 k 级索引,我们发现要查找的元素 x 比 y 大比 z 小,所以,我们需要从 y 处下降到 k-1 级索引继续查找,k-1级索引中比 y 大比 z 小的只有一个 w,所以在 k-1 级索引中,我们遍历的元素最多就是 y、w、z,发现 x 比 w大比 z 小之后,再下降到 k-2 级索引。所以,k-2 级索引最多遍历的元素为 w、u、z。其实每级索引都是类似的道理,每级索引中都是两个结点抽出一个结点作为上一级索引的结点。 现在我们得出结论:当每级索引都是两个结点抽出一个结点作为上一级索引的结点时,每一层最多遍历3个结点。
跳表的索引高度 h = log2n,且每层索引最多遍历 3 个元素。所以跳表中查找一个元素的时间复杂度为 O(3*logn),省略常数即:O(logn)。
空间复杂度
跳表通过建立索引,来提高查找元素的效率,就是典型的“空间换时间”的思想,所以在空间上做了一些牺牲,那空间复杂度到底是多少呢?
假如原始链表包含 n 个元素,则一级索引元素个数为 n/2、二级索引元素个数为 n/4、三级索引元素个数为 n/8 以此类推。所以,索引节点的总和是:n/2 + n/4 + n/8 + … + 8 + 4 + 2 = n-2,空间复杂度是 O(n)。
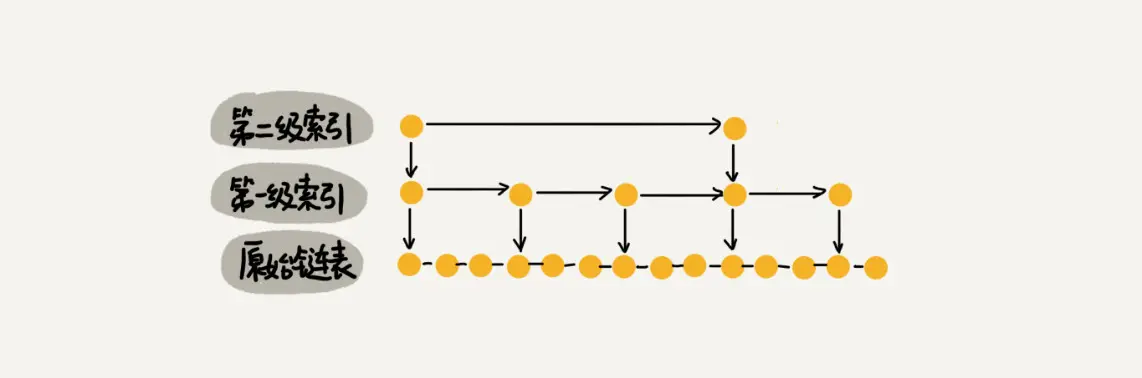
如下图所示:如果每三个结点抽一个结点做为索引,索引总和数就是 n/3 + n/9 + n/27 + … + 9 + 3 + 1= n/2,减少了一半。所以我们可以通过较少索引数来减少空间复杂度,但是相应的肯定会造成查找效率有一定下降,我们可以根据我们的应用场景来控制这个阈值,看我们更注重时间还是空间。
但是,索引结点往往只需要存储 key 和几个指针,并不需要存储完整的对象,所以当对象比索引结点大很多时,索引占用的额外空间就可以忽略了。举个例子:我们现在需要用跳表来给所有学生建索引,学生有很多属性:学号、姓名、性别、身份证号、年龄、家庭住址、身高、体重等。学生的各种属性只需要在原始链表中存储一份即可,我们只需要用学生的学号(int 类型的数据)建立索引,所以索引相对原始数据而言,占用的空间可以忽略。
跳表查找
插入数据看起来也很简单,跳表的原始链表需要保持有序,所以我们会向查找元素一样,找到元素应该插入的位置。如下图所示,要插入数据6,整个过程类似于查找6,整个的查找路径为 1、1、1、4、4、5。查找到第底层原始链表的元素 5 时,发现 5 小于 6 但是后继节点 7 大于 6,所以应该把 6 插入到 5 之后 7 之前。整个时间复杂度为查找元素的时间复杂度 O(logn)。
如下图所示,假如一直往原始列表中添加数据,但是不更新索引,就可能出现两个索引节点之间数据非常多的情况,极端情况,跳表退化为单链表,从而使得查找效率从 O(logn) 退化为 O(n)。那这种问题该怎么解决呢?我们需要在插入数据的时候,索引节点也需要相应的增加、或者重建索引,来避免查找效率的退化。那我们该如何去维护这个索引呢?
比较容易理解的做法就是完全重建索引,我们每次插入数据后,都把这个跳表的索引删掉全部重建,重建索引的时间复杂度是多少呢?因为索引的空间复杂度是 O(n),即:索引节点的个数是 O(n) 级别,每次完全重新建一个 O(n) 级别的索引,时间复杂度也是 O(n) 。造成的后果是:为了维护索引,导致每次插入数据的时间复杂度变成了 O(n)。
那有没有其他效率比较高的方式来维护索引呢?假如跳表每一层的晋升概率是 1/2,最理想的索引就是在原始链表中每隔一个元素抽取一个元素做为一级索引。换种说法,我们在原始链表中随机的选 n/2 个元素做为一级索引是不是也能通过索引提高查找的效率呢? 当然可以了,因为一般随机选的元素相对来说都是比较均匀的。如下图所示,随机选择了n/2 个元素做为一级索引,虽然不是每隔一个元素抽取一个,但是对于查找效率来讲,影响不大,比如我们想找元素 16,仍然可以通过一级索引,使得遍历路径较少了将近一半。如果抽取的一级索引的元素恰好是前一半的元素 1、3、4、5、7、8,那么查找效率确实没有提升,但是这样的概率太小了。我们可以认为:当原始链表中元素数量足够大,且抽取足够随机的话,我们得到的索引是均匀的。我们要清楚设计良好的数据结构都是为了应对大数据量的场景,如果原始链表只有 5 个元素,那么依次遍历 5 个元素也没有关系,因为数据量太少了。所以,我们可以维护一个这样的索引:随机选 n/2 个元素做为一级索引、随机选 n/4 个元素做为二级索引、随机选 n/8 个元素做为三级索引,依次类推,一直到最顶层索引。这里每层索引的元素个数已经确定,且每层索引元素选取的足够随机,所以可以通过索引来提升跳表的查找效率。
那代码该如何实现,才能使跳表满足上述这个样子呢?可以在每次新插入元素的时候,尽量让该元素有 1/2 的几率建立一级索引、1/4 的几率建立二级索引、1/8 的几率建立三级索引,以此类推,就能满足我们上面的条件。现在我们就需要一个概率算法帮我们把控这个 1/2、1/4、1/8 ... ,当每次有数据要插入时,先通过概率算法告诉我们这个元素需要插入到几级索引中,然后开始维护索引并把数据插入到原始链表中。下面开始讲解这个概率算法代码如何实现。
我们可以实现一个 randomLevel() 方法,该方法会随机生成 1~MAX_LEVEL 之间的数(MAX_LEVEL表示索引的最高层数),且该方法有 1/2 的概率返回 1、1/4 的概率返回 2、1/8的概率返回 3,以此类推。
- randomLevel() 方法返回 1 表示当前插入的该元素不需要建索引,只需要存储数据到原始链表即可(概率 1/2)
- randomLevel() 方法返回 2 表示当前插入的该元素需要建一级索引(概率 1/4)
- randomLevel() 方法返回 3 表示当前插入的该元素需要建二级索引(概率 1/8)
- randomLevel() 方法返回 4 表示当前插入的该元素需要建三级索引(概率 1/16)
- ... 以此类推
所以,通过 randomLevel() 方法,我们可以控制整个跳表各级索引中元素的个数。重点来了:randomLevel() 方法返回 2 的时候会建立一级索引,我们想要一级索引中元素个数占原始数据的 1/2,但是 randomLevel() 方法返回 2 的概率为 1/4,那是不是有矛盾呢?明明说好的 1/2,结果一级索引元素个数怎么变成了原始链表的 1/4?我们先看下图,应该就明白了。
假设我们在插入元素 6 的时候,randomLevel() 方法返回 1,则我们不会为 6 建立索引。插入 7 的时候,randomLevel() 方法返回3 ,所以我们需要为元素 7 建立二级索引。这里我们发现了一个特点:当建立二级索引的时候,同时也会建立一级索引;当建立三级索引时,同时也会建立一级、二级索引。所以,一级索引中元素的个数等于 [ 原始链表元素个数 ] * [ randomLevel() 方法返回值 > 1 的概率 ]。因为 randomLevel() 方法返回值 > 1就会建索引,凡是建索引,无论几级索引必然有一级索引,所以一级索引中元素个数占原始数据个数的比率为 randomLevel() 方法返回值 > 1 的概率。那 randomLevel() 方法返回值 > 1 的概率是多少呢?因为 randomLevel() 方法随机生成 1~MAX_LEVEL 的数字,且 randomLevel() 方法返回值 1 的概率为 1/2,则 randomLevel() 方法返回值 > 1 的概率为 1 - 1/2 = 1/2。即通过上述流程实现了一级索引中元素个数占原始数据个数的 1/2。
同理,当 randomLevel() 方法返回值 > 2 时,会建立二级或二级以上索引,都会在二级索引中增加元素,因此二级索引中元素个数占原始数据的比率为 randomLevel() 方法返回值 > 2 的概率。 randomLevel() 方法返回值 > 2 的概率为 1 减去 randomLevel() = 1 或 =2 的概率,即 1 - 1/2 - 1/4 = 1/4。OK,达到了我们设计的目标:二级索引中元素个数占原始数据的 1/4。
以此类推,可以得出,遵守以下两个条件:
- randomLevel() 方法,随机生成 1~MAX_LEVEL 之间的数(MAX_LEVEL表示索引的最高层数),且有 1/2的概率返回 1、1/4的概率返回 2、1/8的概率返回 3 ...
- randomLevel() 方法返回 1 不建索引、返回2建一级索引、返回 3 建二级索引、返回 4 建三级索引 ...
就可以满足我们想要的结果,即:一级索引中元素个数应该占原始数据的 1/2,二级索引中元素个数占原始数据的 1/4,三级索引中元素个数占原始数据的 1/8 ,依次类推,一直到最顶层索引。
整体思路大家应该明白了,那插入数据时维护索引的时间复杂度是多少呢?元素插入到单链表的时间复杂度为 O(1),我们索引的高度最多为 logn,当插入一个元素 x 时,最坏的情况就是元素 x 需要插入到每层索引中,所以插入数据到各层索引中,最坏时间复杂度是
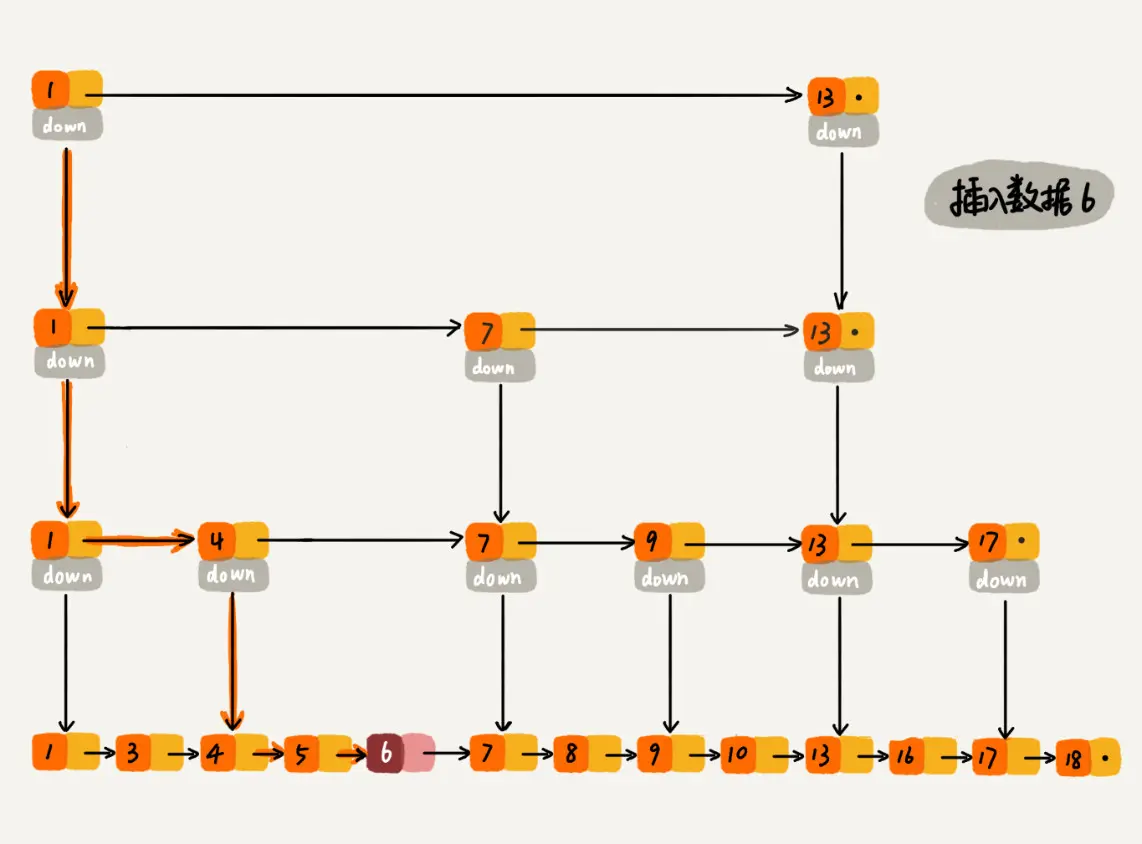
过程大概理解了,再通过一个例子描述一下跳表插入数据的全流程。现在我们要插入数据 6 到跳表中,首先 randomLevel() 返回 3,表示需要建二级索引,即:一级索引和二级索引需要增加元素 6。该跳表目前最高三级索引,首先找到三级索引的 1,发现 6 比 1大比 13小,所以,从 1 下沉到二级索引。
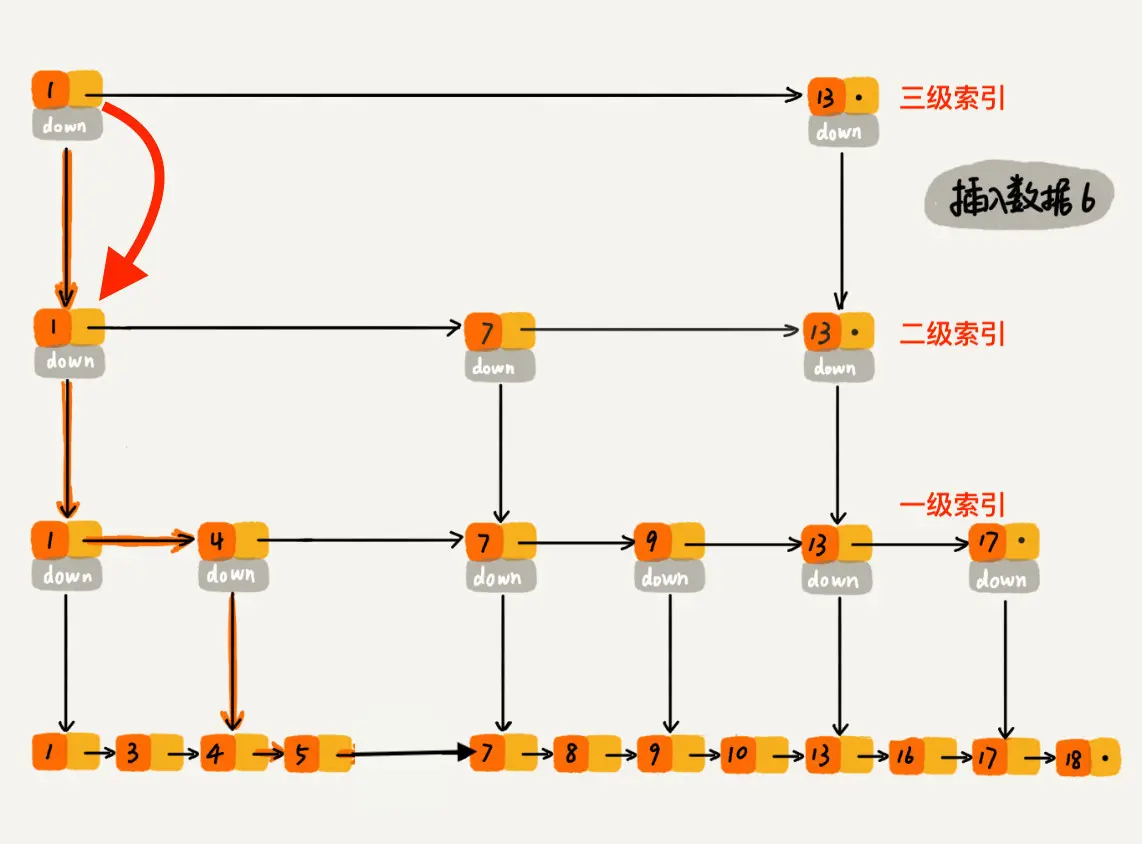
下沉到二级索引后,发现 6 比 1 大比 7 小,此时需要在二级索引中 1 和 7 之间加一个元素6 ,并从元素 1 继续下沉到一级索引。
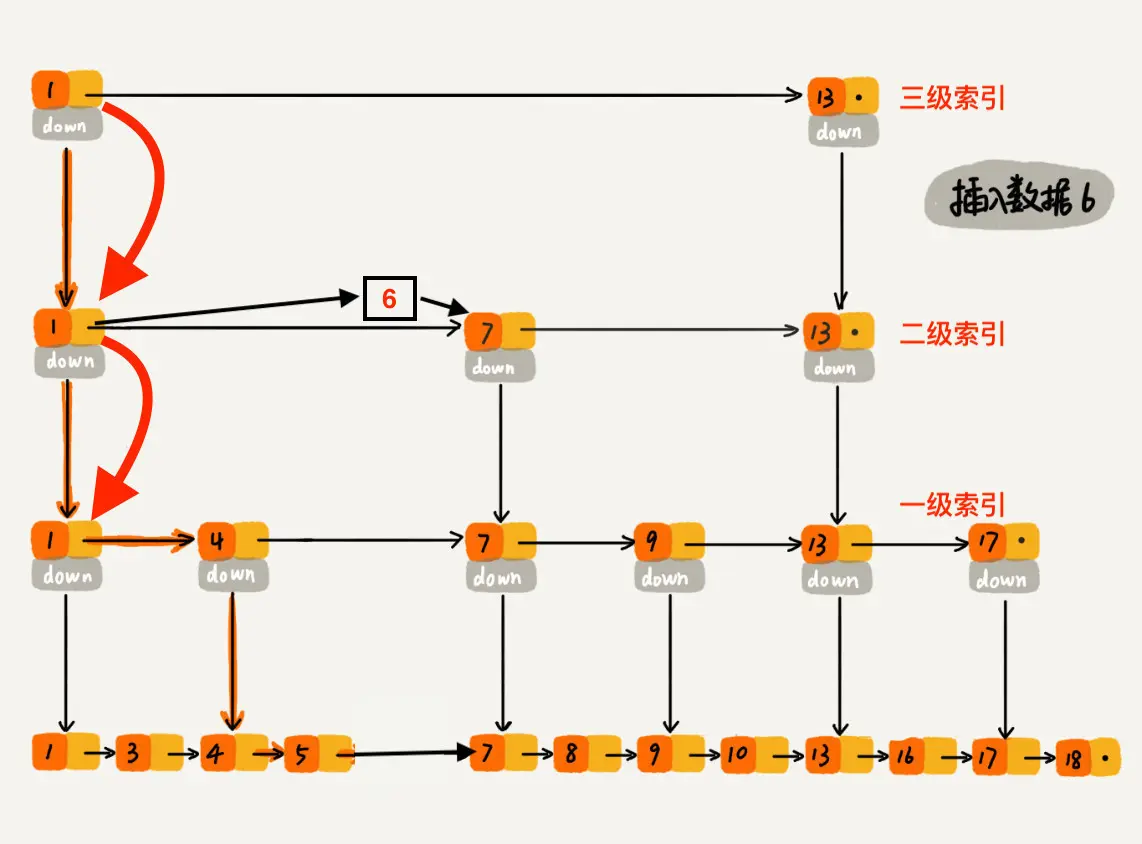
下沉到一级索引后,发现 6 比 1 大比 4 大,所以往后查找,发现 6 比 4 大比 7 小,此时需要在一级索引中 4 和 7 之间加一个元素 6 ,并把二级索引的 6 指向 一级索引的 6,最后,从元素 4 继续下沉到原始链表。
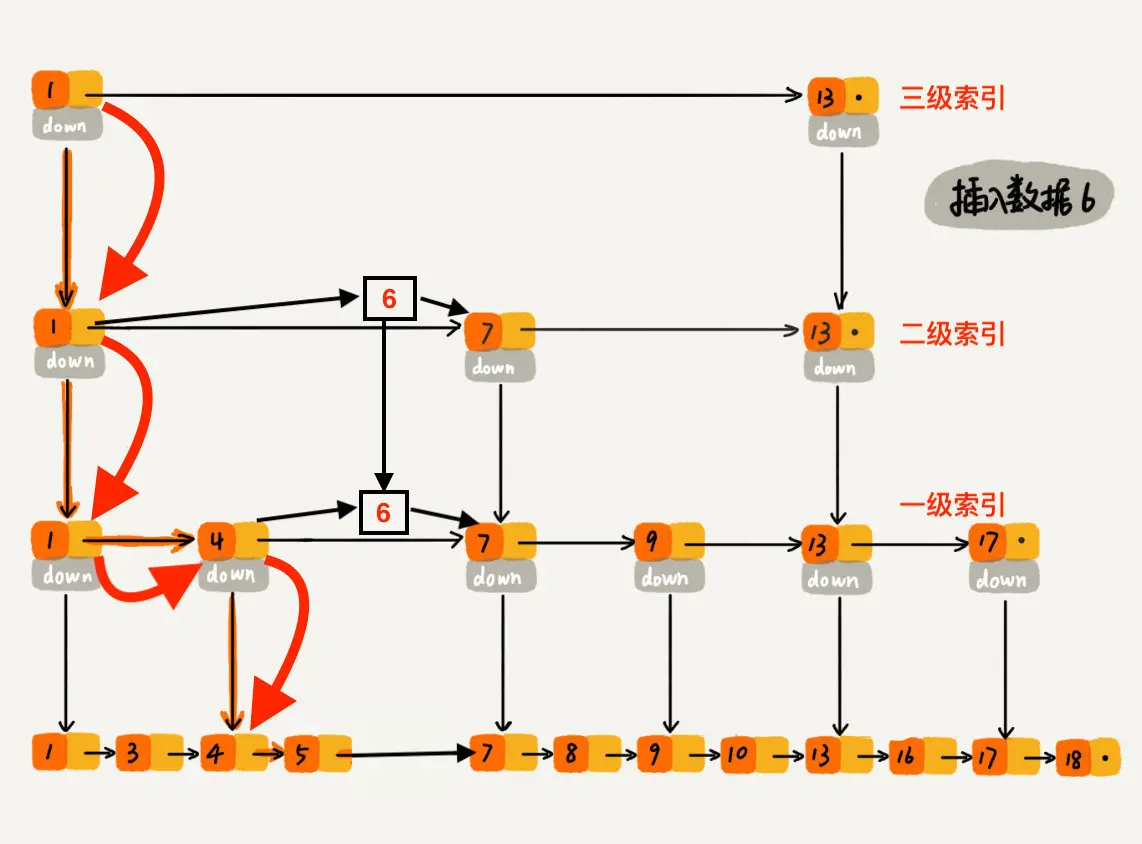
下沉到原始链表后,就比较简单了,发现 4、5 比 6小,7比6大,所以将6插入到 5 和 7 之间即可,整个插入过程结束。
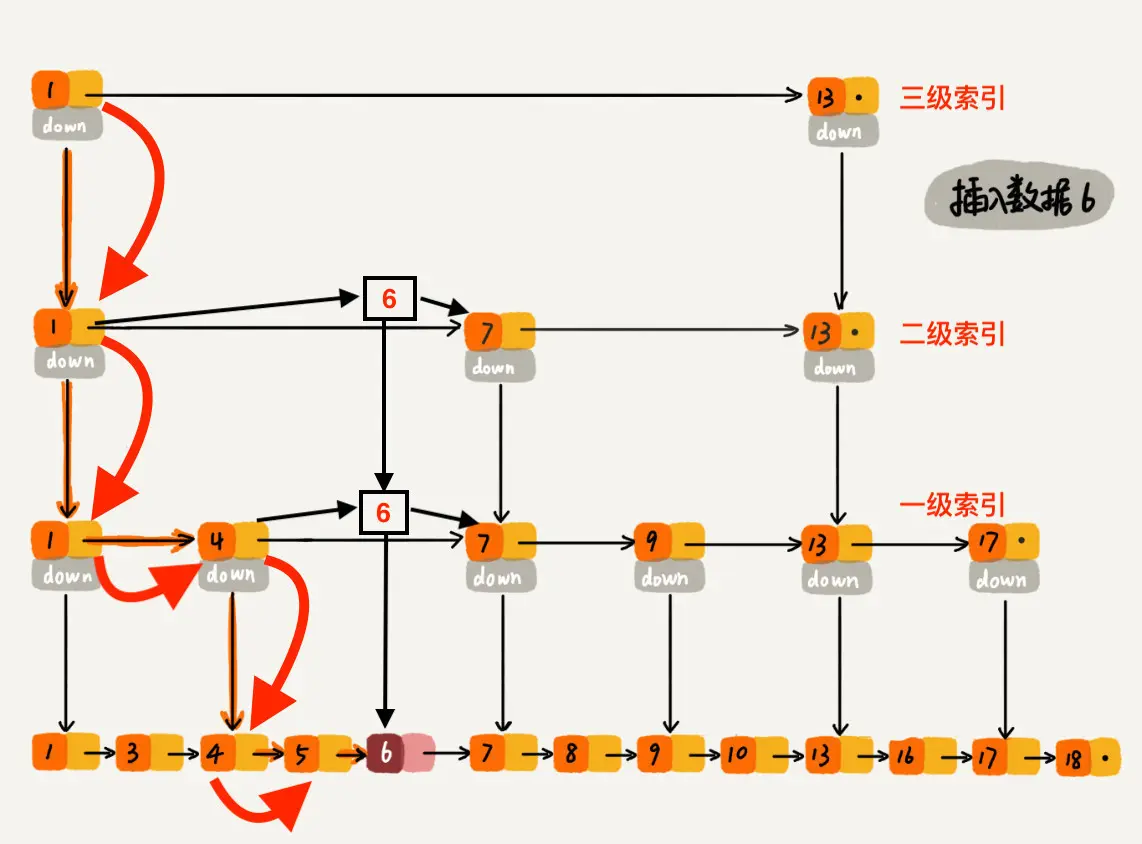
整个插入过程的路径与查找元素路径类似, 每层索引中插入元素的时间复杂度 O(1),所以整个插入的时间复杂度是
删除数据
跳表删除数据时,要把索引中对应节点也要删掉。如下图所示,如果要删除元素 9,需要把原始链表中的 9 和第一级索引的 9 都删除掉。
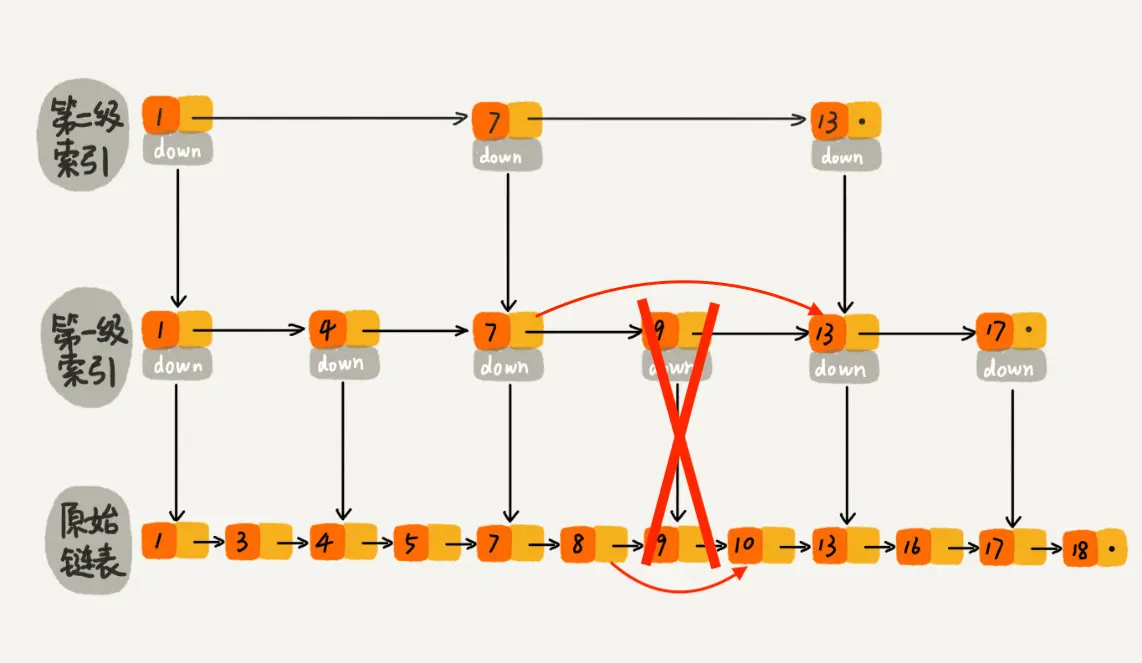
删除的时间复杂度
删除元素的过程跟查找元素的过程类似,只不过在查找的路径上如果发现了要删除的元素 x,则执行删除操作。跳表中,每一层索引其实都是一个有序的单链表,单链表删除元素的时间复杂度为 O(1),索引层数为